Datenintensive Systeme – wie sie etwa KI- oder IoT-basierte Systeme darstellen – sind das Rückgrat unserer modernen Welt und finden Anwendung in verschiedenen Domänen wie dem Gesundheitswesen, Handel, Produktion oder im Finanzbereich. Diese Systeme sind stark auf die Qualität der zu verarbeiteten Daten angewiesen, was das Testen der Daten zu einem kritischen Bestandteil in der Qualitätssicherung dieser Systeme macht.
Das Testen von Daten ist jedoch eine arbeitsintensive Tätigkeit und bringt mehrere Herausforderungen mit sich, wie die Priorisierung, welche Daten getestet werden sollen und wie gründlich diese Tests durchgeführt werden müssen. Die ständig zunehmende Menge an Daten verschärft diese Probleme und erfordert neue Ansätze, um eine effiziente und effektive Datentestung sicherzustellen.
In diesem Beitrag stellen wir ein Framework zum risikobasierten Testen von Daten vor. Das risikobasierte Testen von Daten ist ein vielversprechender Ansatz, um die beschriebenen Probleme zu adressieren und selektives Testen von Daten in der Praxis zu ermöglichen [1]. Das Framework wurde im Rahmen der Dissertation von Harald Foidl an der Universität Innsbruck unter Betreuung von Prof. Michael Felderer entwickelt und in mehreren Fachbeiträgen publiziert.
Warum das Testen von Daten herausfordernd ist
Das Testen von Daten beschreibt die kontinuierliche Prüfung von Daten, um ihre Qualität hinsichtlich von Eigenschaften wie Vollständigkeit, Konsistenz oder Genauigkeit zu beurteilen. Dabei werden verschiedene Techniken und Verfahren wie Datentyp- und Datenwertbereichsprüfungen angewendet. Im Rahmen dieser Datenprüfungen stehen Softwareentwickler:innen, Dateningenieur:innen und Tester:innen oft vor der Herausforderung, geeignete Prüfkriterien zu definieren, um Daten von minderer Qualität zu identifizieren. Exakte Datenprüfkriterien sind essenziell, um eine Balance zwischen falsch positiven und falsch negativen Prüfergebnissen zu finden und die Systemleistung nicht durch die induzierten Latenzen der Validierungsprüfungen zu beeinträchtigen. Aufgrund der domänenspezifischen Natur der Datenqualität können präzise Validierungsgrenzen in der Regel jedoch nur mit Hilfe von Fachexpert:innen festgelegt werden, was die Datenvalidierung zu einer zeit- und arbeitsintensiven Tätigkeit macht.
Darüber hinaus macht der Umstand, dass moderne datengetriebene Systeme Tausende von verschiedenen Daten verarbeiten, eine vollständige Prüfung aller Daten praktisch unmöglich.
Aktuelle Datenvalidierungslösungen unterstützen IT-Expert:innen nicht ausreichend bei der Bestimmung der Validierungsstrenge oder Priorisierung. Die wenigen Lösungen, die eine Automatisierung der Datenvalidierung anstreben, sind entweder auf spezifische Datentypen [2] oder Fehlertypen [3] beschränkt. Diese Umstände machen das Testen von Daten besonders herausfordernd, wenn man berücksichtigt, wie sensibel maschinelle Lernmodelle und ihre Algorithmen auf die Qualität der Daten reagieren.
Risikobasiertes (Software) Testen
Die Idee, Entscheidungen risikobasiert zu treffen, ist nicht neu. In der Softwareentwicklung hat sich das risikobasierte Testen bereits seit einiger Zeit etabliert [4]. Beim risikobasierten Testen von Software werden die Testbemühungen auf Basis der potenziellen Risiken, die mit einem Softwaresystem verbunden sind, priorisiert. Zentrales Element des risikobasierten Testens ist, wie der Name bereits verrät, das Risikokonzept. Dieses verbindet die Wahrscheinlichkeit, dass ein Teil der Software fehlerhaft ist, mit den Auswirkungen eines Fehlers in diesem Teil der Software zu einem Risikowert. Auf Basis dieses Risikowerts werden dann Entscheidungen entlang des gesamten Testprozesses getroffen, zum Beispiel die Priorisierung der Testfälle.
Risikobasiertes Testen von Daten – ein Framework
Die Kernidee beim risikobasierten Testen von Daten ist es, den Fokus auf die Daten mit dem höchsten Risiko niedriger Datenqualität zu legen. Das Risiko niedriger Datenqualität wird bestimmt durch die Wahrscheinlichkeit, dass Daten von minderer Qualität sind (Probability), und durch die Auswirkungen dieser niedrigen Datenqualität (Impact) auf das System unter Test.
Systeme unter Test sind typischerweise datenintensive Systeme, die sich durch eine große Menge an zu verarbeitenden Eingangsdaten (Input data signals) aus diversen Datenquellen (Data sources) auszeichnen. Diese Systeme nehmen alle Eingangsdaten auf (Data ingestion) und generieren durch Datenbereinigung (Data curation) und -verarbeitung (Data processing) sogenannte Features. Ein Feature setzt sich üblicherweise aus einem oder mehreren Eingangsdaten zusammen. Ein konkretes Beispiel für ein Feature ist die Lagerabnutzung einer Maschine, basierend auf Vibrations-, Akustik- und Temperaturdaten. Anschließend werden die Features in einem datenintensiven System durch Anwendung von Algorithmen des maschinellen Lernens genutzt, um intelligente Entscheidungen zu treffen (Data analytics). Die Lagerabnutzung einer Maschine kann beispielsweise verwendet werden, um Defekte frühzeitig zu erkennen und entsprechende Wartungsmaßnahmen rechtzeitig zu planen (Predictive maintenance).
Das Testen von Daten im Kontext datenintensiver Systeme findet sowohl bei den Eingangsdaten als auch nach den verschiedenen Datenoperationen bei den Features statt. Abbildung 1 zeigt ein datenintensives System und kennzeichnet farblich das Ziel des risikobasierten Testens von Daten, nämlich die Fokussierung auf die Daten mit dem höchsten Risiko niedriger Datenqualität.

Abbildung 1: Risikobasierte Datenvalidierung in einem datenintensiven System
Um dies zu erreichen, verfolgt das entwickelte Framework das Ziel, für jedes Feature in einem datenintensiven System das Risiko schlechter Datenqualität zu ermitteln. Da Eingangsdaten deterministisch Features zugewiesen werden können, ist es einfach möglich, das Risiko schlechter Datenqualität anschließend auf einzelne Eingangsdaten abzuleiten. Überdies ist es auch möglich, Gruppen von Features zu bilden, die eine bestimmte Entität von Interesse darstellen, wie zum Beispiel eine Produktionsanlage.

Abbildung 2: Framework zur risikobasierten Datenvalidierung
Um die Wahrscheinlichkeit niedriger Datenqualität zu bestimmen, können qualitätsrelevante Kriterien wie die intrinsische Qualität von Datenquellen (Data source quality), die Qualität der Pipeline, welche die Daten verarbeitet (Data pipeline quality), oder Indikatoren in den Daten selbst (Data Smells) verwendet werden.
Die Auswirkungen niedriger Datenqualität auf die Performance eines Systems basieren auf der Idee, dass nicht alle Daten mit niedriger Qualität die gleiche negative Auswirkung auf die Systemperformance haben. Ein Kriterium hierfür ist die sogenannte Feature Importance, die beschreibt, welchen Beitrag ein Feature in einem maschinellen Lernmodell auf das Ergebnis hat. Es gibt zahlreiche Algorithmen und Methoden, wie die Feature Importance Ranking Measure oder den LIME Algorithmus, um die Feature Importance zu bestimmen. Neben der Verwendung der Feature Importance können auch Expertenbewertungen herangezogen werden, um die Auswirkungen von schlechter Datenqualität in einem System zu bewerten.
Sobald Wahrscheinlichkeit und Auswirkung für jedes Feature bestimmt wurden, kann das Risiko niedriger Datenqualität anhand von Risikowerten berechnet und den Features entsprechende Risiko Levels in einer Risiko Matrix zugewiesen werden. Anhand der ermittelten Risikowerte bzw. Risiko Levels kann anschließend die Datenprüfstrategie (Data validation strategy) abgeleitet werden. Diese beschreibt die Priorisierung, Strenge, Häufigkeit und die zu verwendeten Techniken der Datenvalidierungstests.
Die Priorisierung liefert Informationen zur Rangfolge von Features basierend auf ihrem Risiko schlechter Datenqualität im Vergleich zueinander. Auf diese Weise können IT-Expert:innen bei der Implementierung von Datenvalidierungstests Features mit hohem Risikoniveau priorisieren. Unter der Strenge der Validierung versteht man die Genauigkeit, mit der Features auf einem bestimmten Risikolevel validiert werden sollten, also die Grenzwerte bzw. Schwellwertbereiche der angewandten Validierungstests. Darüber hinaus können auch spezifische Datenvalidierungstechniken den Risikolevels zugewiesen werden. Beispielsweise können fortgeschrittene statistische Analysen (z.B. Hypothesentests, Korrelationsanalysen) und präzise abgestimmte benutzerdefinierte Datenwertprüfungen dem höchsten Risikolevel zugewiesen werden. Im Gegensatz dazu können eher gewöhnliche Datenqualitätsprüfungen, wie Duplikatprüfungen oder Vollständigkeitsprüfungen, für das niedrigste Risikolevel definiert werden. Darüber hinaus können weitere Entscheidungen im Kontext der Datenvalidierungsstrategie getroffen werden, z.B. die Häufigkeit der Ausführung von Datenvalidierungstests. Das Framework ist in Abbildung 2 konzeptuell dargestellt.
Wahrscheinlichkeit von niedriger Datenqualität
Während die Auswirkungen niedriger Datenqualität relativ einfach ermittelt werden können, ist dies für die Wahrscheinlichkeit niedriger Datenqualität aufgrund der Heterogenität und der vielen potenziellen Einflussfaktoren nicht so einfach möglich. Im Folgenden stellen wir die von uns vorgeschlagenen Kriterien zur Ermittlung der Wahrscheinlichkeit niedriger Datenqualität daher detaillierter vor.
Indikatoren niedriger Datenqualität in den Daten – Data Smells
Angelehnt an das Konzept der Code Smells aus der Softwareentwicklung beschreiben Data Smells kontextunabhängige, datenwertbasierte Indikatoren für latente Datenqualitätsprobleme, die durch schlechte Praktiken verursacht werden und zu zukünftigen Problemen führen können. Latent bedeutet in diesem Zusammenhang, dass die Datenqualitätsprobleme nicht sofort erkennbar sind, jedoch zu Problemen führen können. Data Smells sind durch einen moderaten „Grad an Verdächtigkeit“ gekennzeichnet. Ein Beispiel hierfür ist der Begriff ‘New York‘, der semantisch mehrdeutig ist, da unklar ist, ob er sich auf die Stadt oder den Bundesstaat in den Vereinigten Staaten bezieht. Dies kann in einem Sprachverarbeitungssystem zu fehlerhaften Ergebnissen führen. Eine weitere Eigenschaft von Data Smells ist ihre Kontextunabhängigkeit, was sie zu einer Gefahr für alle Arten von datengetriebenen Systemen macht. Data Smells entstehen üblicherweise durch schlampige Praktiken in der Datenverarbeitung, wie fehlende Integritäts- oder Gültigkeitsprüfungen oder die Verwendung von „Glue Code“. Data Smells können zusätzlichen Code erfordern, um sie zu beseitigen und auch zu Problemen wie Datentypkonvertierungsfehlern führen.

Abbildung 3: Data Smell Katalog
Auf Basis einer Literaturrecherche haben wir einen Katalog typischer Data Smells erstellt, der diese in drei Hauptkategorien einteilt, wie in Abbildung 3 dargestellt. Diese sind Believability Smells, welche semantisch unplausible Datenwerte kennzeichnen (z.B. ein Datum, das weit in der Zukunft liegt: 01.01.4025), Understandability Smells, welche die unangemessene, ungewöhnliche oder mehrdeutige Verwendung von Zeichen, Formaten oder Datentypen beschreiben (z.B. Integer als String kodiert) und Consistency Smells, welche eine inkonsistente Syntax in den Daten beschreiben (z.B. unterschiedliche Kodierung von fehlenden Werten). Eine vollständige Definition aller Smells inklusive Beispielen sowie entwickelte Tools zur Detektierung von Data Smells können im Rahmen der Publikation [5] eingesehen werden.
Qualität der Datenquellen
Die intrinsische Qualität der Datenquellen kann einen erheblichen Einfluss auf die Qualität der von dieser Quelle bereitgestellten Daten haben. Zum Beispiel kann davon ausgegangen werden, dass eine Datenquelle mit einem schlechten Datenschema oder fehlenden Datenintegritätsbeschränkungen Daten niedriger Qualität liefert. Entsprechend haben wir einen Ansatz entwickelt, der Qualitätscharakteristiken sowie Eigenschaften von Datenquellen berücksichtigt, die einen Einfluss auf die bereitgestellten Daten haben. Dazu haben wir Datenquellen in Datenspeicher (z.B. Datenbanken) und Datenanbieter (z.B. Sensoren) unterteilt. Für Datenspeicher haben wir ein Qualitätsmodell entwickelt, das verschiedene Qualitätscharakteristika eines Datenspeichers messen kann, wie etwa den Normalisierungsgrad des Datenschemas oder die Qualität der Metadaten (Abbildung 4).

Abbildung 4: Datenspeicher-Qualitätsmodell
Für Datenanbieter haben wir einen Katalog für das industrielle Umfeld entwickelt, mit dem es möglich ist, Datenanbieter wie Sensoren oder Anlagen hinsichtlich ihrer Wahrscheinlichkeit, Daten niedriger Qualität zu liefern, zu bewerten. Hierzu werden Kriterien wie die Art der Konnektivität (drahtlos oder kabelgebunden) oder die Art der Energieversorgung (Batterie oder Festverdrahtet) verwendet (Abbildung 5).

Abbildung 5: Eigenschaftskatalog von Datenanbietern
Das entwickelte Qualitätsmodel für Datenspeicher sowie der Katalog zur Bewertung von Datenanbietern aus dem industriellen Umfeld sind in folgender Publikation [6] einsehbar.
Datenverarbeitungsqualität – Datenpipeline Qualität
Als drittes und letztes Kriterium eignet sich die Qualität der Pipelines, die die Daten verarbeiten, um die Wahrscheinlichkeit von niederer Datenqualität zu bestimmen. Speziell sind Faktoren interessant, welche die Fähigkeit von Datenpipelines beeinflussen können, Daten von hoher Qualität zu liefern. Zum Beispiel kann eine fehlende Definition, wie ‘N/A‘‚ Werte in Pipelines behandelt werden sollen, ungültige Daten bei einer Datenaggregation verursachen. Basierend auf einer Analyse von datenverarbeitungsbezogenen Issues in GitHub Projekten sowie einer Untersuchung von Problemen von Entwickler:innen bei der Datenverarbeitung im Rahmen von StackOverflow Posts haben wir eine Taxonomie mit entsprechenden Einflussfaktoren erstellt. Die Taxonomie ist in Abbildung 6 dargestellt und beschreibt 41 Einflussfaktoren, aufgeteilt in die Themen „Data“, „Development & Deployment“, „Infrastructure“, „Life Cycle Management“ und „Processing“. Eine detaillierte Beschreibung aller Faktoren kann in der Publikation [7] eingesehen werden.
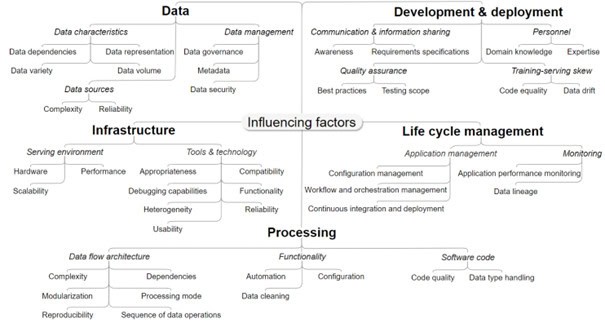
Abbildung 6: Taxonomie von Datenpipeline-Einflussfaktoren
Fazit
Daten sind in der heutigen Zeit ein Kernbestandteil intelligenter Softwaresysteme. Die Zuverlässigkeit und Funktionalität solcher datenintensiver Systeme hängen jedoch stark von der Qualität der Daten ab. Eine stringente Prüfung der Datenqualität ist daher unumgänglich, um eine hohe Zuverlässigkeit dieser Systeme sicherzustellen. Die enorme und stetig wachsende Menge der zu prüfenden Daten bringt traditionelle Datenvalidierungskonzepte jedoch an den Rand der Anwendbarkeit. Risikobasiertes Testen von Daten kann diesem Problem entgegenwirken und ermöglicht das effiziente Testen durch Fokussierung der Tests auf die Daten mit dem höchsten Risiko von schlechter Datenqualität.
Das in diesem Beitrag vorgestellte Framework ermöglicht ein selektives Testen von Daten in heterogenen Umgebungen und kann die Effektivität und Produktivität von Datenvalidierungen in der Praxis steigern. Überdies können die entworfenen Konzepte und Techniken zur Bestimmung der Wahrscheinlichkeit von niedriger Datenqualität in anderen Bereichen Anwendung finden. Zum Beispiel könnten Data Smells im Rahmen des Testens von Software verwendet werden, um subtile Implementierungsfehler (z.B. Edge Cases) zu erkennen. Die zugrundeliegende Idee hierbei ist, dass subtile Implementierungsfehler oft unkonventionelle Datenprobleme verursachen, die als Data Smells sichtbar werden können.
Referenzen
[1] H. Foidl und M. Felderer, „Risk-based data validation in machine learning-based software systems“, in Proceedings of the 3rd ACM SIGSOFT international workshop on machine learning techniques for software quality evaluation, 2019, S. 13–18.
[2] J. Song und Y. He, „Auto-Validate: Unsupervised Data Validation Using Data-Domain Patterns Inferred from Data Lakes“, in Proceedings of the 2021 International Conference on Management of Data, Virtual Event China: ACM, Juni 2021, S. 1678–1691. doi: 10.1145/3448016.3457250.
[3] S. Redyuk, Z. Kaoudi, V. Markl, und S. Schelter, „Automating Data Quality Validation for Dynamic Data Ingestion.“, in EDBT, 2021, S. 61–72.
[4] M. Felderer, M.-F. Wendland, und I. Schieferdecker, „Risk-based testing“, in Leveraging applications of formal methods, verification and validation. Specialized techniques and applications, T. Margaria und B. Steffen, Hrsg., Berlin, Heidelberg: Springer Berlin Heidelberg, 2014, S. 274–276.
[5] H. Foidl, M. Felderer, und R. Ramler, „Data smells: categories, causes and consequences, and detection of suspicious data in AI-based systems“, in Proceedings of the 1st International Conference on AI Engineering: Software Engineering for AI, Pittsburgh Pennsylvania: ACM, Mai 2022, S. 229–239. doi: 10.1145/3522664.3528590.
[6] H. Foidl und M. Felderer, „An approach for assessing industrial IoT data sources to determine their data trustworthiness“, Internet Things, Bd. 22, S. 100735, Juli 2023, doi: 10.1016/j.iot.2023.100735.
[7] H. Foidl, V. Golendukhina, R. Ramler, und M. Felderer, „Data Pipeline Quality: Influencing Factors, Root Causes of Data-related Issues, and Processing Problem Areas for Developers“, J. Syst. Softw. Revis., 2023.
Zu den Autoren
Harald Foidl, Universität Innsbruck
Harald Foidl absolvierte die HTL für Elektronik und Technische Informatik in Innsbruck, bevor er an der Universität Innsbruck einen Bachelorabschluss in Wirtschaftswissenschaften und einen Masterabschluss in Wirtschaftsinformatik erlangte. Im Jahr 2023 schloss er sein Doktoratsstudium in Informatik erfolgreich ab. Seine Hauptinteressen liegen in der Entwicklung und Architektur datengetriebener Softwaresysteme zur Prozessoptimierung. Aktuell verantwortet er die maschinelle Fertigung (SMT) und Digitalisierung der Produktion bei Kontron Austria.
Michael Felderer, DLR, Universität Innsbruck, Universität zu Köln
Prof. Dr. Michael Felderer ist Direktor des Instituts für Softwaretechnologie am Deutschen Zentrum für Luft- und Raumfahrt e.V. (DLR) sowie Professor an den Universitäten Köln und Innsbruck. Michael Felderer ist international ausgewiesener Experte zu den Themen Softwaretesten, Softwarequalität sowie dem Wechselspiel zwischen KI und Software Engineering. Neben seiner wissenschaftlichen Tätigkeit berät er auch Unternehmen und ist regelmäßiger Sprecher auf Konferenzen.


Michael Felderer (links), Harald Foidl (rechts)
Der Beitrag Risikobasiertes Testen von Daten erschien zuerst auf Austrian Testing Board.
Jetzt REQUIREMENTS ENGINEERING Trainingskurse, wie IREB-CPRE Foundation Level, IREB CPRE Advanced Level RE@Agile, RE@Agile Primer (IREB Certified Professional for Requirements Engineering), IREB CPRE Advanced Level Elicitation